Module Nine: Hands-on With Text Analysis
10 March 2022

Important Proviso: Last year, we had a “two day” special study break due to COVID-19, and I actually found the pace of the course worked well with this.
Let’s use this week in the same spirit, and we’ll be focusing on an in-class collaborative activity. So no readings, but let’s work together in class on our coding skills.
Catch your breath and you can also get caught up on this or other courses.
Readings for this Week
NO READINGS THIS WEEK BUT WE WILL HAVE OUR MEETING AS SCHEDULED.
Want to Meet with Me?
As always, you can book a 30-minute meeting with me via Calendly. Use this link here. If there are no times that are available, just send me an email and we can work something out.
This will create a Microsoft Teams appointment. The URL for the Teams link will be in the calendar invitation e-mailed to you.
Hands-on Lesson
Getting Text and Playing with It
Find a “Collection” at the Internet Archive that you will use. Make sure to keep the text string from the URL. For example, I will use The Economist.
Let’s start by downloading the plain text of a file. See below.
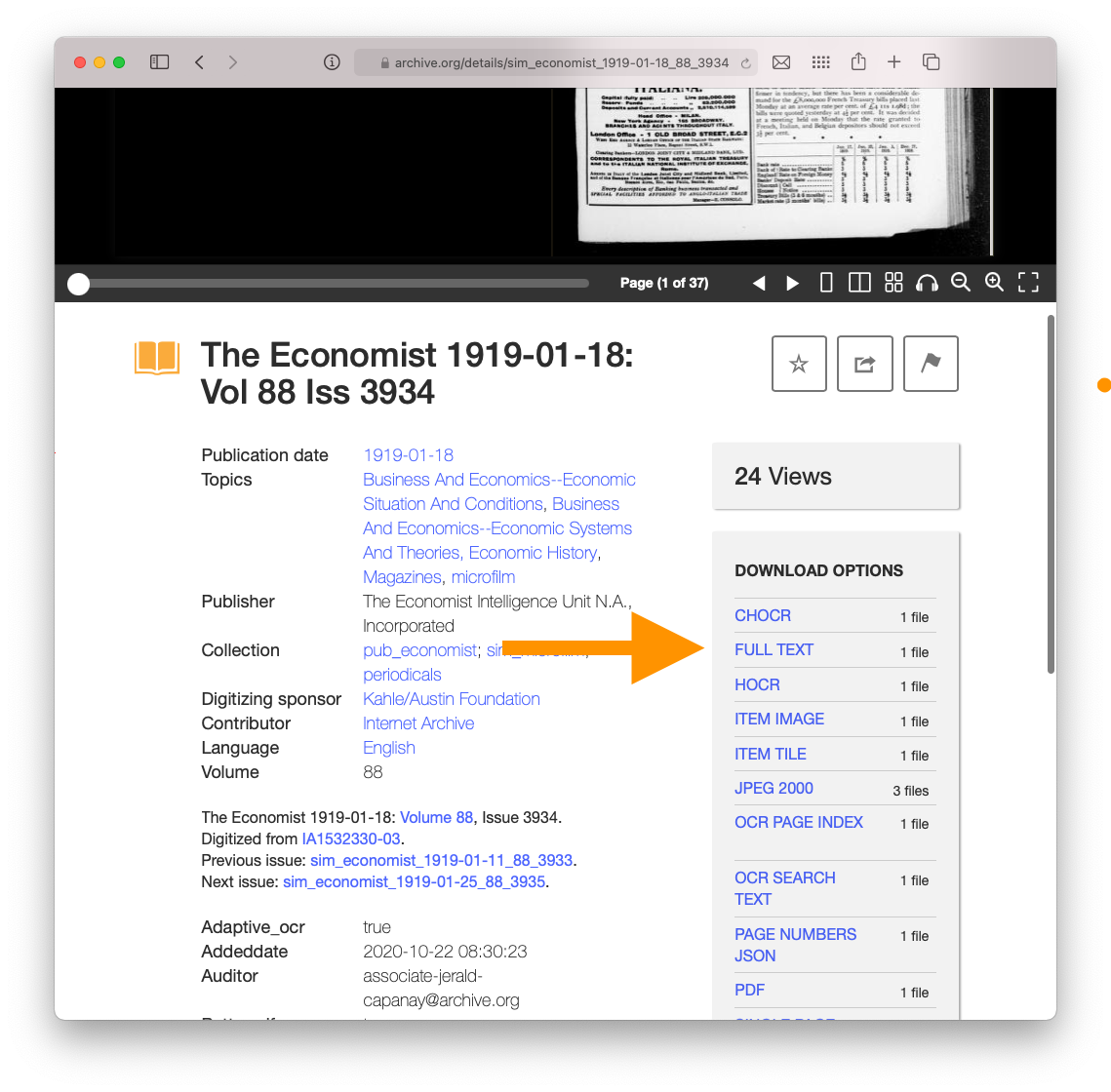
- We’ll then play with the easy way to explore: by putting it into Voyant Tools. You can either upload the text file or paste it into the “reveal text” box.
- We will then work with Voyant together.
Let’s Scale this up Computationally
- Start up a Google Collab notebook. Click on “New Notebook.” It should look like this.
- Let’s make sure it works. You can add “Text” and “Code” panels. We will add a “Text” panel explaining that this is HIST 640. Then we will add a “Code” panel with the following piece of code.
print('hello world')When you hit the “play” button or you press Ctrl+Enter, it will run that cell.
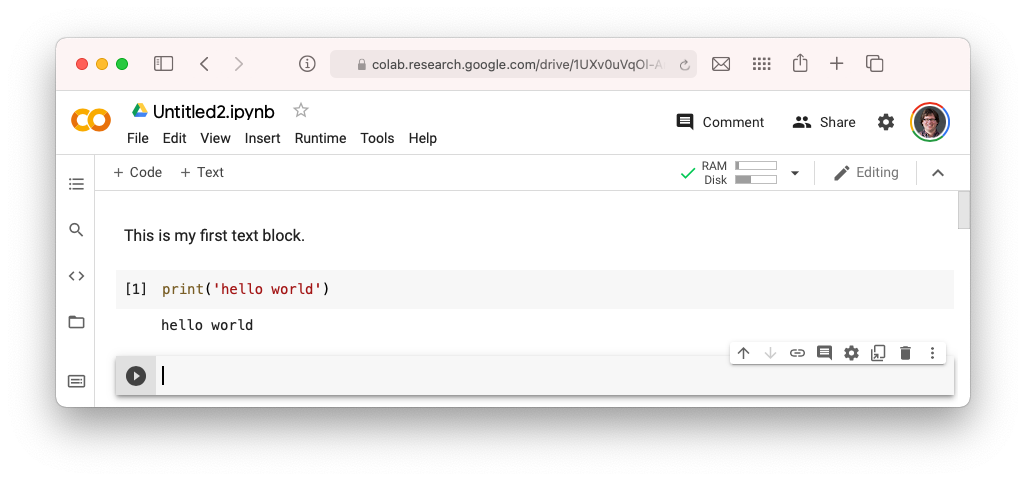
Huzzah. It is working!
- Now we want to work with Internet Archive data. Luckily, the Internet Archive has a Python library! A library is a set of commands that we can use to work directly with the Internet Archive.
Let’s install it by running the following cell.
!sudo pip install internetarchive > /dev/null- Now let’s work with your collection. I am going to use the Economist in these examples, but you should swap in your own collection. We’ll have fun.
First up, let’s see what resources we have in a collection. This also makes sure that the library is working.
!ia search "collection:pub_economist" --itemlist | headYou should see something like:
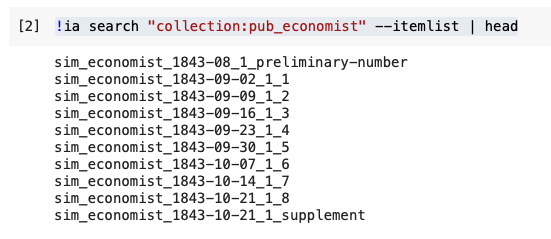
Now let’s look at an individual item. It can get a bit complicated, but here you see is the actual item itself. Let’s see what formats we have available.
!ia metadata --formats sim_economist_1843-09-02_1_1 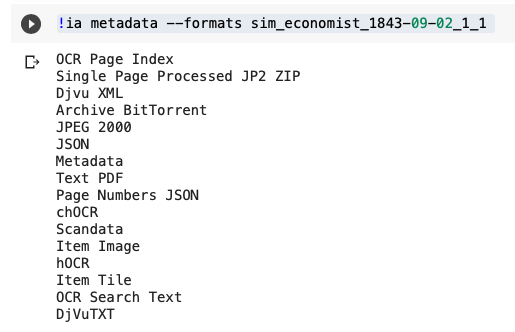
I’ll walk you through what these are.
- Let’s download the text.
!ia download sim_economist_1843-09-02_1_1 --format='DjVuTXT'You will see success when it is done downloading!

We can find it in our “downloads” folder on the side of Google Collab.
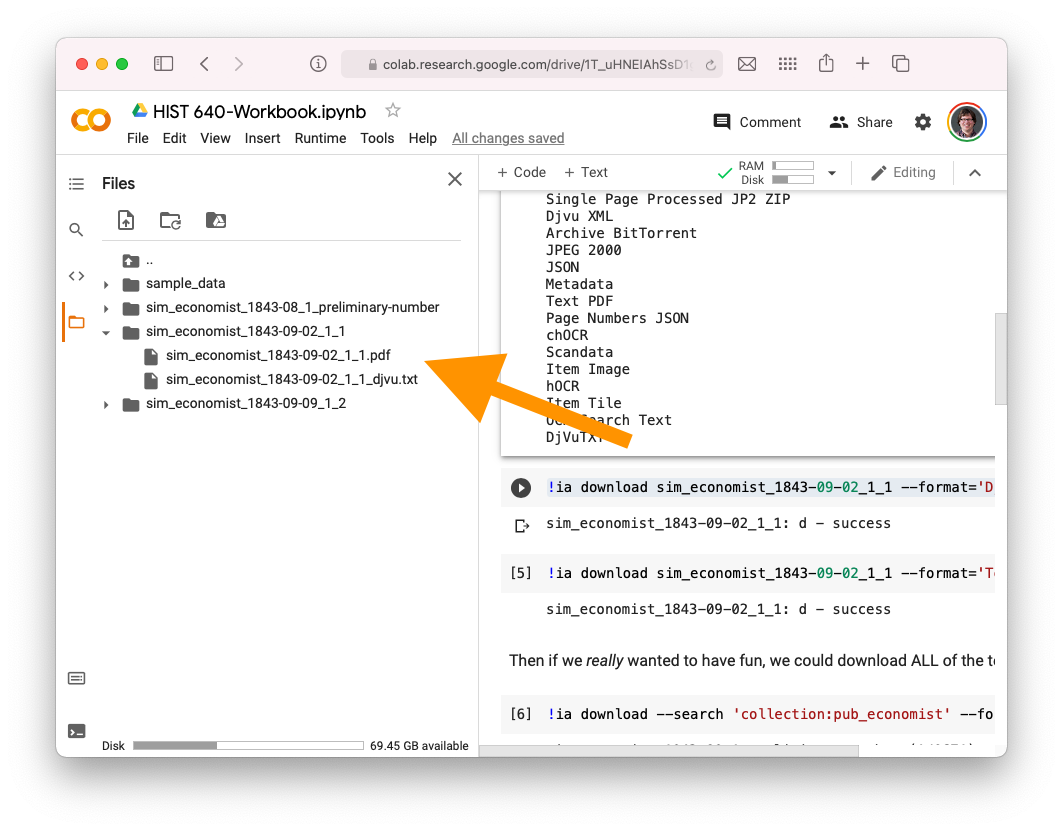
Let’s download the text. See, we could also pop this into Voyant if we wanted to. Or we could also download lots of text to pop into Voyant.. the possibilities are limitless.
- Let’s say we want to build an epic PDF collection. Let’s try the same command as above, but this time we’ll change the format to PDF. It would look a bit like this:
!ia download sim_economist_1843-09-02_1_1 --format='Text PDF'Let’s imagine we wanted to download all of them.
!ia download --search 'collection:pub_economist' --format='DjVuTXT'- Now we’ll play a bit around with this.
How can we analyze text in Python?
We’ll start with ‘strings’ - little phrases, just to conceptually see what’s going on. We’ll start with some basic Waterloo phrases, and then we will eventually load in our Economist downloaded text file.
I am adopting this from this great Normalizing Textual Data with Python lesson from the Programming Historian, written by William J. Turke land Adam Crymble. Shout out to their CC-BY 4.0 license for letting this happen.
- Let’s create some strings:
wordstring = 'The University of Waterloo has 7,000 geese on its campus. '
wordstring += 'While geese are normally friendly, they should be approached with caution. '
wordstring += 'However, I really like Geese.'Now if we type
wordstringWe will see:

- We can also make it into a list:
wordlist = wordstring.split()and then type
wordlist- Let’s count the words!
wordfreq = []
for w in wordlist:
wordfreq.append(wordlist.count(w))And then let’s see what the string, the list, the frequencies, and the pairs are.
print("String\n" + wordstring +"\n")
print("List\n" + str(wordlist) + "\n")
print("Frequencies\n" + str(wordfreq) + "\n")
print("Pairs\n" + str(list(zip(wordlist, wordfreq))))- Uh oh! Here’s a problem. There are 3 geese in the string, but only two show up. Now we’ve got to begin NORMALIZING it.
We can make a string lowercase by doing this:
wordstring.lower()Let’s try to re-do all the above, but make the string lowercase. It might take a few minutes so take your time.
We then run into the problem of periods. Check this out, we can do a simple find and replace as well.
wordstring.replace(".","")That would remove all the periods and replace them with nothing.
Let’s Bring it All Together
- Let’s bring that text file into Python. To do so, we can click on the three dots next to the file and select “copy path.”
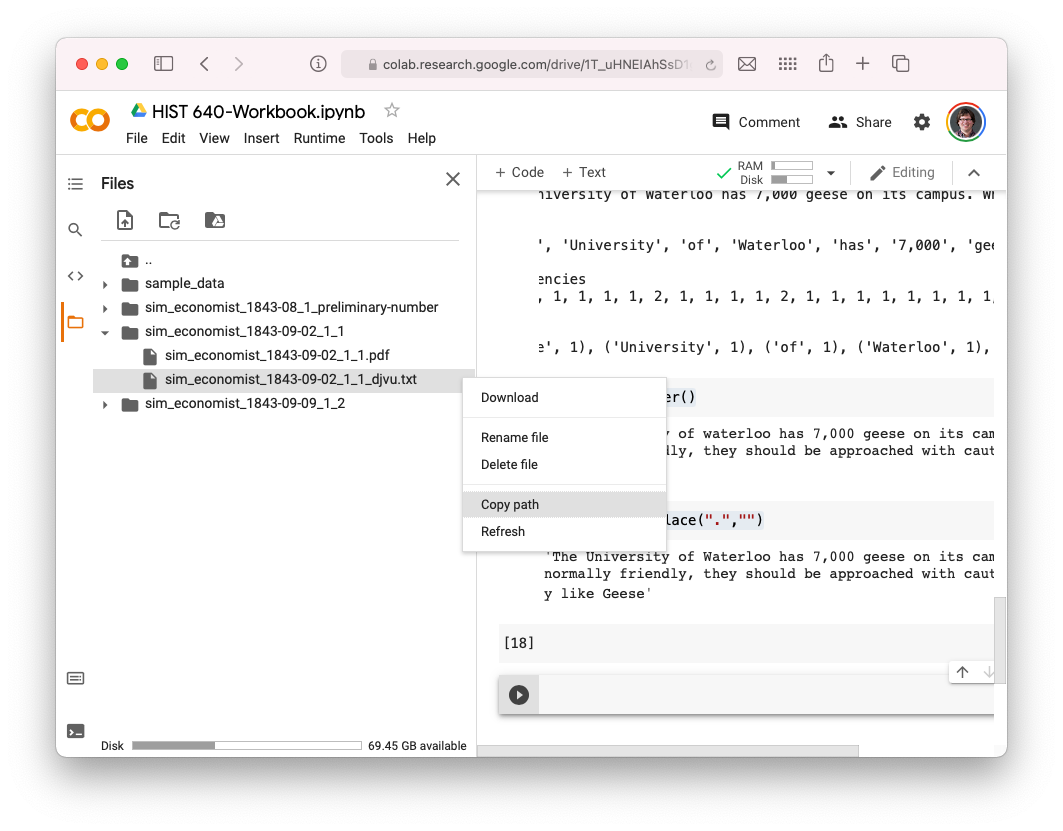
Let’s put that into a new variable called “filename”
filename = "/content/sim_economist_1843-09-02_1_1/sim_economist_1843-09-02_1_1_djvu.txt"Now let’s open it, using this:
from pathlib import Path
txt = Path(filename).read_text()And let’s see what’s in there, using the print command:
print(txt)Now that’s like our Goose string from before! Let’s play around a bit with counting some words in it, etc. Notice here I put the lower() command in with the split() command to make it a bit more streamlined.
wordlist = txt.lower().split()
wordfreq = []
for w in wordlist:
wordfreq.append(wordlist.count(w))
print("Frequencies\n" + str(wordfreq) + "\n")
print("Pairs\n" + str(list(zip(wordlist, wordfreq))))We’ll just play a little bit and discuss here.